Intel CEO Lip-Bu Tan used his Q1 earnings call to spotlight a 10,000x increase in AI inference compute demand over two years, marking what industry observers are calling the "inference inflection."
The chip giant's earnings presentation showed CPU utilisation climbing as AI applications move from experimental to production workloads. Tan's comments align with recent statements from OpenAI CEO Sam Altman, who said the company must "become an AI inference company now."
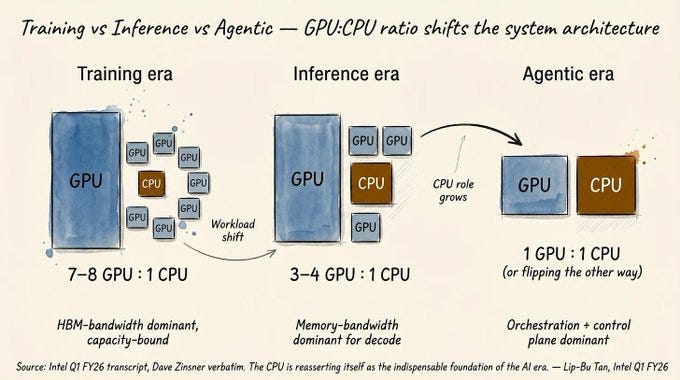
The shift reflects a broader industry transition. While companies spent heavily on GPU clusters for model training over the past two years, production AI systems require different compute architectures. CPU-intensive tasks include running reinforcement learning environments, code execution sandboxes, and the growing category of AI agents that interact with software systems.
Why CPUs Matter for AI Production
Unlike training workloads that benefit from GPU parallelism, many inference tasks require the sequential processing and memory bandwidth that CPUs provide. Anthropic's Claude and other reasoning models increasingly use multi-step processes that lean on traditional compute resources.
SemiAnalysis research suggests the industry faces a CPU shortage partly due to underinvestment during the GPU rush. Companies diverted budgets from routine hardware refreshes to fund AI infrastructure, creating pent-up demand as systems reach end-of-life.
The trend extends beyond CPUs. Nvidia's recent acquisitions of Groq and partnerships with Cerebras signal recognition that inference workloads need specialised architectures. Prefill and decode operations are increasingly disaggregated across different chip types.
"We are now at that positive flywheel system," Nvidia CEO Jensen Huang said at GTC, describing how inference demand creates a self-reinforcing cycle of capability and usage growth.
Intel's positioning comes as the company attempts to regain ground in AI infrastructure. The earnings call data suggests traditional chip makers may benefit as the industry matures beyond pure GPU scaling toward heterogeneous compute environments optimised for production AI workloads.
💬 Discussion
Sign in to join the discussion.
Sign in →No comments yet — be the first.